
Q Learning
1. Q-Learning
Off-Policy Learning 알고리즘 중에서 Off-policy MC와 Off-policy TD가 있지만 Importance sampling문제 때문에 새로운 방법이 필요하다고 말했었습니다. Off-Policy learning을 하는데 가장 좋은 알고리즘은 Q Learning입니다. 방법은 다음과 같습니다. 현재 state S에서 action을 선택하는 것은 behaviour policy를 따라서 선택합니다. TD에서 udpate할 때는 one-step을 bootstrap하는데 이 때 다음 state의 action을 선택하는 데는 behaviour policy와는 다른 policy(alternative policy)를 사용하면 Importance Sampling이 필요하지 않습니다. 이전의 Off-Policy에서는 Value function을 사용했었는데 여기서는 action-value function을 사용함으로서 다음 action까지 선택을 해야하는데 그 때 다른 policy를 사용한다는 것입니다.

2. Off-Policy Control with Q-Learning
이 Q learning 알고리즘 중에서 가장 유명한 것이 아래입니다.
Behaviour policy로는 $$\epsilon$$-greedy w.r.t. Q(s,a)
Target policy(alternative policy)로는 greedy w.r.t. Q(s,a)
를 택한 알고리즘입니다. 이전에 Off-policy의 장점이 exploratory policy를 따르면서도 optimal policy를 학습할 수 있다고 했는데 그게 바로 이 알고리즘입니다. greedy한 policy로 학습을 진행하면 수렴을 빨리 하는데 충분히 탐험을 하지 않았기 때문에 local에 빠지기 쉽습니다. 그래서 탐험을 위해서 $$\epsilon$$-greedy policy를 사용하면 탐험을 계속하는데 이렇게 학습하면 수렴속도가 느려져서 학습속도가 느려지게 됩니다. 이를 해결하기 위한 방법이 $$\epsilon$$을 시간에 따라 decay시키는 방법과 아래와 같이 Q learning을 사용하는 것입니다.

아래 알고리즘은 사실 Bellman Optimality Equation을 사용한 Value Iteration을 이용한 것입니다. Optimal value function끼리의 관계식을 이용해서 update를 하는 것입니다. 이렇게 update를 할 때 optimal action-value function에 수렴하게 됩니다.

알고리즘은 아래와 같습니다.

3.Sarsa vs Q-learning
이렇게 Q-learning에 대해서 살펴봐도 직관적으로 Q-learning이 어떤 방식으로 작동하는지 잘 와닿지 않을 것입니다. Q-learning을 이해하려면 SARSA와 비교해보는 것이 좋습니다. Sutton이 이 두 가지를 비교할 수 있는 예제를 제시했습니다."Cliff Walking"이라는 예제입니다.
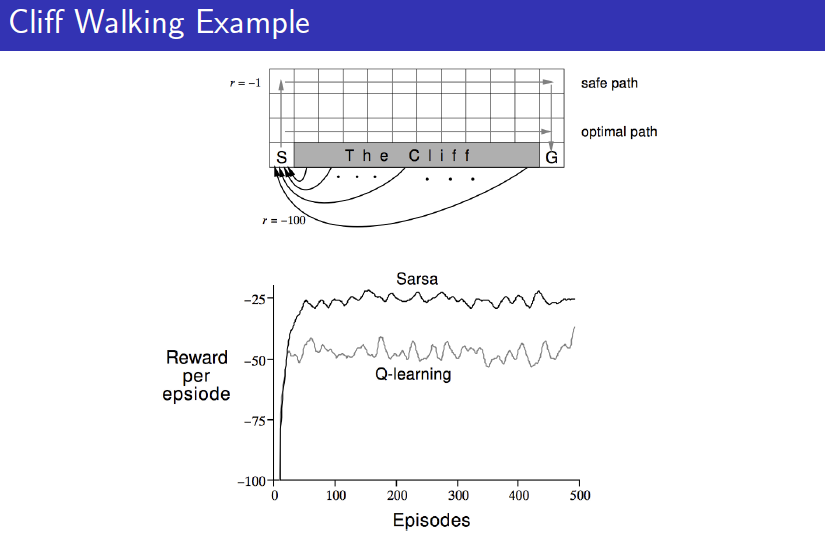
이 예제에서 목표는 S라는 start state에서 시작해서 Goal까지 가는 optimal path를 찾는 것입니다. 그림에 나와있는 Cliff에 빠져버리면 -100의 reward를 받고 time-step마다 reward를 -1씩 받는 문제라서 절벽에 빠지지 않고 goal까지 가능한 한 빠르게 도착하는 것이 목표입니다.
눈으로 딱 봐도 그림에 있는 optimal path가 답이라고 생각합니다. SARSA와 Q-learning 모두 다 $$\epsilon$$-greedy한 policy로 움직입니다. 따라서 더러는 Cliff에 빠져버리기도 합니다. 차이는 SARSA는 on-policy라서 그렇게 Cliff에 빠져버리는 결과로 인해 그 주변의 상태들의 value를 낮다고 판단합니다. 하지만 Q-learing의 경우에는 비록 $$\epsilon$$-greedy로 인해 Cliff에 빠져버릴지라도 자신이 직접 체험한 그 결과가 아니라 greedy한 policy로 인한 Q function을 이용해서 업데이트합니다. 따라서 Cliff 근처의 길도 Q-learning은 optimal path라고 판단할 수 있어서 이 문제의 경우 SARSA보다는 Q-learning이 적합하다고 할 수 있습니다.
SARSA에서 탐험을 위해서 $$\epsilon$$-greedy를 사용했지만 결국은 그로인해서 정작 에이전트가 optimal로 수렴하지 못하는 현상들이 발생한 것입니다. 따라서 Q-learning의 등장 이후로는 많은 문제에서 Q-learning이 더 효율적으로 문제를 풀었기 때문에 강화학습에서 Q-learning은 기본적인 알고리즘으로 자리를 잡게 됩니다.
Last updated